Gli acidi
nucleici - Storia, struttura, meccanismi
Scoperta
degli acidi nucleici
Il primo
ricercatore che intuì l’ereditarietà dei caratteri fu un abate boemo Mendel
( 1822-1884 ) che attraverso lavori sugli incroci vegetali, osservò come
i caratteri della pianta fossero ereditari, incrociando piante con
caratteristiche differenti tra di loro vide che i caratteri si ripetevano con
frequenza variabile, si parlò di fenotipo, ovvero di tutto ciò
che è visibile e dipendeva dal genotipo, ciò che è scritto
nel codice genetico. I caratteri che si ripetevano vennero detti dominanti
quelli invece che saltavano più generazioni prima di essere visibili, vennero
detti recessivi. Fu lo scienziato tedesco Miescher nel 1869 che
all’università di Tubinga isolò dal pus dei bendaggi una sostanza acida che
definì “nucleina” in seguito si rivelò essere il DNA. Però anche questo
lavoro, come quello precedente, non ebbe il giusto riconoscimento. Nel 1928 con
gli esperimenti del microbiologo inglese Griffith, ci fu la certezza
dell’esistenza di un fattore chimico in grado di modificare con le proprie
caratteristiche organismi aventi caratteri differenti. Famoso il suo
esperimento con il calore uccise alcuni pneumococchi ne mescolò l’estratto con
batteri vivi ma senza capsula; osservò che i batteri avevano perso la
possibilità di costruire la capsula e quindi di danneggiare le cellule di topi;
dopo questa manipolazione ricostruivano il proprio codice portando il topo a
morte. Fu un altro microbiologo inglese Avery dimostrò che i batteri potevano scambiarsi
pezzi di una sostanza chimica chiamata “fattore trasformante”. Era il 1944 e si
accettava l’idea che era una sostanza che custodiva il segreto dell’ereditarietà. Nel 1951 alcuni
ricercatori riuscirono finalmente a
determinare la struttura di questa molecola Watson Crick e Rosalind Franklin arrivando ad
ottenere una fotografia chiara della molecola grazie ai raggi X. Fu definita la
struttura e nel 1962 ottennero il premio Nobel. Nel 1957 Kornberg,
scopre l’enzima DNA-polimerasi che ha la funzione di scrivere una nuova
molecola di DNA. Nel 1960 viene scoperto l’RNA messaggero, nel 1966 viene
decifrato il codice genetico, nel 1968 viene scoperta la DNA ligasi.
Arriviamo al 1970 per avere il primo tentativo di introdurre un gene in una
cellula malata, nasce così il DNA ricombinante. Nel 1975 viene descritto il
primo metodo per la sintesi del DNA ma
si deve arrivare al 1988 perché si attiva il progetto “genoma umano” con
l’intento di identificare tutti i geni che compongono il DNA umano. Le ricerche
le scoperte dopo questo periodo di tempo sono numerose e tutte importanti. In
circa 150 di studio, le scoperte sono state di fondamentale importanza; saranno
i prossimi anni che ci daranno un idea precisa sugli effetti di queste
ricerche.
Ora cerchiamo di
rispondere ad una serie di domanda che un interlocutore fantasma:
1.
Come è fatto il DNA: fu grazie alla fotografia con i raggi X che
si riuscì a comprendere la struttura di questa molecola. Due filamenti
antiparalleli formati da polinucleotidi, avvolti ad elica intorno ad un asse
comune. L’asse è formato da molecole zuccherine il desossiribosio legato
attraverso legami 3’5’ e 5’ 3’ con l’acido fosforico. Da notare che la polarità
della catena è tale da presentare il primo ossidrile dello zucchero sempre
libero sia in posizione 5’ o in 3’, le cariche negative sono bilanciate da ioni
bivalenti per i procarioti, da proteine basiche per gli eucarioti. Le basi sono
rivolte verso l’interno dell’elica , si trovano una di fronte all’altra con una distanza di 2,85 A. Mediante legami
ad idrogeno si legano e vengono dette basi complementari. La timina si lega con
l’ adenina , la guanina si lega con la citosina; il rapporto è 1:1
questa osservazione fu fatta dal chimico viennese Chargaff. Il DNA è una spirale avvolta in senso
destrogiro. Scaldando l’acido si ottiene il distacco delle due eliche
(denaturazione) raffreddando si ottiene l’accoppiamento (rinaturazione); la
temperatura mediamente si aggira sugli 80 - 90° C, questa temperatura dipende
dalla composizione in basi dell’acido. Con una composizione delle basi intorno
al 50% la temperatura di fusione si aggira intorno a valori 69°C, mentre con
una percentuale intorno al 68% la temperatura si aggira intorno ai 80°C. La molecola dell’acido si può denaturare
anche con acidi o basi. Nelle cellule procariote
dove non esiste il nucleo il DNA è
avvolto da una serie di proteine basiche chiamate istoni; nelle cellule
eucariote invece il DNA è avvolto da proteine chiamate cromatina. Nelle cellule procariote tutte le
informazioni sono contenute in una sola molecola di DNA circolare con peso
dell’ordine di 2*109, nelle cellule eucariote sono contenute più
molecole di DNA, in questo tipo di cellule il DNA è organizzato a formare i
cromosomi, caratteristici per forma e numero. La struttura dell’acido in natura
ed in condizioni normali viene detta del tipo B destrogira con le
basi perpendicolari all’asse dell’elica, in condizioni particolari esistono
altre due strutture dette A e Z. La
prima struttura non esiste in vivo e
corrisponde alla molecola disidratata. La seconda struttura è un elica
sinistrorsa lo scheletro presenta un
andamento ondulato, la percentuali di basi G e C è decisamente alta, potrebbe
essere un riconoscimento particolare. I
livelli di super avvolgimento sono per l’acido degli eucarioti una
caratteristica fondamentale, si può pensare come il filo avvolto a formare una
matassa, tante matasse legate assieme formano una struttura super avvolta. Nel
minimo spazio sono contenute enormi informazioni genetiche. L’avvolgimento
avviene grazie alle proteine presenti in associazioni con l’acido, l’unità
elementare è detta nucleosoma il super avvolgimento è il polinucleosoma.
Formule chimiche dei
componenti del DNA:
Quattro basi: le
prime due puriniche: adenina e guanina,
le altre due pirimidiniche: citosina e uracile.
|
|
|
|
|
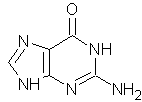
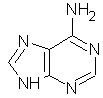
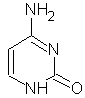
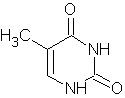
ADENINA
GUANINA
CITOSINA TIMINA
Le basi puriniche sono legate allo zucchero in posizione 9 le basi pirimidiniche in
posizione 1’ lo zucchero a sua volta lega le basi in posizione 1’ in posizione 3’ e 5’ alternativamente
lega l’acido orto fosforico. Lo scheletro della molecola è costituito dallo
zucchero e dall’acido orto fosforico, le basi sono orientate verso la parte
interna della alfa elica che si produce.
Nella figura sotto riportata è possibile osservare l’avvolgimento
dell’elica del DNA.
|
|
|
|
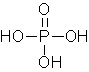
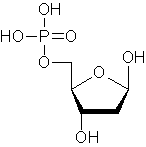
Acido fosforico Desossiribosio Forma ad alfa elica
2.
Come si duplica il DNA: ogni filamento è lo stampo molecolare su cui
si adatta la sequenza e quindi il filamento complementare. Il DNA si trova
avvolto intorno a strutture particolari dette istoni proteine ricche di aminoacidi basiche che
interagiscono con il DNA mediante l’acido fosforico. Le proteine hanno
un basso peso molecolare molecole relativamente piccole. Quando però la cellula
deve duplicarsi, allora il DNA prende forma visibile detta cromosoma
strutture formate da proteine e da acido
nucleico. Il primo passo è lo
svolgimento dell’elica ad opera dell’enzima detto elicasi, strutture
proteiche tengono separate le due eliche vincendo le forze di attrazione
l’enzima si chiama topoisomerasi. Vi sono piccoli frammenti di RNA
innesco che vengono sintetizzati prima che la sintesi del DNA abbia inizio
da un enzima detto primasi,. il
complesso si chiama replisoma.
Nel punto dove il DNA si svolge si forma una forcella di replicazione.
La sintesi è operata da un enzima chiamato DNA polimerasi, in grado di leggere il filamento stampo e di
aggiungere una alla volta le basi tri fosfato, di creare il legame tra le basi e saldare i due
filamenti in modo da formare la doppia elica. Nel 1960 Okazaki osservò
che i due filamenti venivano sintetizzati con la stessa velocità ma con
modalità differenti; uno in modo continuo 5’- 3’ detto “ filamento veloce
“, l’altro in modo discontinuo 3’- 5’ detto “ filamento ritardato “. In
questo senso la sintesi procede a piccoli gruppi, si formano dei frammenti che
vengono uniti successivamente da un enzima detto DNA ligasi, l’elica si ricompone. Questi frammenti sono
formati da circa 2000 basi. Il processo di copiatura è di circa 700 nucleotidi
al secondo, nei batteri è di 50 nucleotidi al secondo. La sintesi fu definita semi
conservativa, perché un braccio di un elica è quella di origine. I piccoli
frammenti di RNA innesco servono da attacco all’enzima, è un segnale di
riconoscimento.
3.
Esistono solo poche polimerasi: nel 1970 studiando altri microrganismi furono scoperte altri
enzimi le polimerasi II e III. La prima serve a riparare errori di trascrizione
la seconda alla sintesi del DNA nei batteri. Sono enzimi costituiti a loro
volta da altre unità enzimatiche, il complesso viene chiamato oligomeri.
4.
L’innesco rimane sempre attaccato: l’innesco viene rimosso da specifici
enzimi, non appena i frammenti vengono saldati dalle ligasi. L’ RNA che funge
da innesco corrisponde al primo segmento del
filamento da sintetizzare, fornisce un terminale 3’ libero del
desossiribosio a cui vengono legate le successive unità.
5.
Come possono i virus che possiedono RNA
replicarsi: i virus a RNA
possono replicarsi perché possiedono un
enzima chiamato DNA polimerasi RNA dipendente chiamato anche trascrittasi
inversa che trascrive l’RNA virale in un filamento di DNA complementare,
formando un ibrido RNA - DNA; successivamente l’enzima degrada l’ RNA e si
replica con il DNA a singolo filamento
un secondo filamento di DNA.
6.
La struttura del DNA: il DNA di forma circolare nei
batteri, nelle altre cellule di organismi superiori il DNA è organizzato in forme filamentose chiamate
cromosomi. Il DNA di un mammifero e formato da circa 5,5*109 coppie
di basi. Se tutte le molecole fossero unite linearmente coprirebbero una
distanza di circa 2 metri. Impossibile, infatti e allora la chiave per
risolvere questo dubbio, risolto con la scoperta di proteine chiamate istoni
piccole di dimensioni ricche di aminoacidi basici e perciò si possono
associare con i residui di acido fosforico. Tanti istoni possono fungere come
un gomitolo dove viene avvolto il filo di lana. I filamenti non sono tutti omogenei, il tratto di DNA che lega due
strutture non presenta nessun gene. Ci può essere ancora una seconda struttura
dove avviene un altro avvolgimento che accorcia ancora la molecola.
7.
E le mutazioni cosa possono generare: le mutazioni sono alterazioni dovute
a fattori fisici, chimici, ambientali o altro. Queste alterazioni possono
essere semplici come lo scambio di una base azotata con un'altra, oppure più
complesso, quali la perdita o l’aggiunta di una base o più basi oppure lo
spostamento di tratti di materiale genetico all’interno di un cromosoma o da
due cromosomi. Oppure le basi vengono modificate come l’aggiunta di gruppi
particolari come la mutilazione o la dimerizzazione. Non tutte le mutazioni
possono essere letali, basti pensare comunque l’enzima che sintetizza il DNA
può correggere alcune alterazioni, ripristinando l’antica struttura. Però le
mutazioni se ripetute ed estese su tanta parte della molecola possono essere
letali. Possono essere trasmesse alle progenie se colpisce il DNA della linea germinale. Oggi vi sono numerose
prove che dimostrano come il cancro può insorgere da profonde alterazioni di
alcuni geni chiamato oncogeni che codificano proteine che hanno perso la capacità
di svolgere correttamente il loro ruolo e la loro funzione. Una cellula con un
oncogene perde il controllo dell’attività proliferativi. Così le malattie
genetiche, dovute ad alterazioni profonde del DNA, dove pezzi di geni possono
sparire o essere sostituiti. Quando avviene la sintesi proteica le proteine non
sono certo proteine normalmente presenti nella cellula. Queste alterazioni
possono anche insorgere nel corso della vita, oppure alla nascita. Le malattie
genetiche possono causare gravi ritardi mentali, diminuita capacita di
trasporto dell’ossigeno nel sangue e così via.
8.
Il DNA le biotecnologie, la genetica: bisogna fare delle distinzioni ben
nette altrimenti si può fare confusione. La genetica si occupa dello studio dei
geni, ovvero quei pezzi di DNA che sono responsabili dei caratteri di un
individuo; la manipolazione dei geni produce nuovi organismi batterici, virali,
animali, vegetali per sintetizzare nuove proteine, altrimenti impossibili da
produrre con le tecniche usuali.
9.
Adesso parliamo di RNA: molto simile al DNA, questo acido è formato da quattro basi
l’uracile sostituisce la timina, lo zucchero è il ribosio e l’acido fosforico.
Formato da una sola catena, molto più corto del DNA, viene sintetizzato
copiando un braccio del DNA con RNA
polimerasi DNA dipendente. Esistono tre
differenti tipi di RNA il primo chiamato messaggero, che ha il compito
di portare il messaggio genetico al di fuori del nucleo per poi guidare la
sintesi proteica. Possiede un estremità in posizione 5’ con una sequenza
di 64 basi non codificanti. Durante il
passaggio dal nucleo al citoplasma l’acido perde una serie di basi, divenendo
più corto. Le parti che si perdono vengono chiamate introni, quelle
invece che vengono trascritte vengono chiamate esoni. L’ RNA ribosomiale
è responsabile della formazione dei ribosomi unitamente a proteine dal basso
peso molecolare. Ultimo ma non meno importante l’ RNA transfer utile per
il trasporto degli aminoacidi nella traduzione. Quest’ultimo acido nucleico
possiede una zona definita anticodon
per la lettura del messaggero, alla sua estremità 3’ si attaccano gli
aminoacidi. Durante la sintesi degli RNA un solo braccio del DNA viene letto,
con l’intervento di numerosi enzimi che hanno il compito di trascrivere tutta
la sequenza. Identificato il pezzo di DNA da leggere, interviene il fattore sigma,
enzima necessario per la lettura del promotore. L’elica si apre rendendo le
basi visibili, l’enzima aggiunge tutte le basi con il principio della
complementarietà. Alla fine il pezzo trascritto viene rimosso dalla presenza di
un fattore definito rho. .
Alcune malattie avvengono per errori nella
fase di modificazione, i trascritti non sono completi.
Formule chimiche dei
componenti del RNA:
Le quattro basi
sono due puriniche l’adenina e la guanina e due basi pirimidiniche l’uracile e
la citosina.
|
|
|
|
|
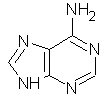
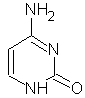
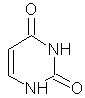
ADENINA GUANINA CITOSINA URACILE
Lo zucchero è il
ribosio e l’acido orto fosforico:
|
|
|
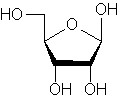
RIBOSIO ACIDO FOSFORICO
L’RNA a singolo filamento presenta il legame
della base purinica in posizione 9, con le basi pirimidiniche in posizione 1, lo zucchero lega le basi in posizione 1’
l’acido fosforico in posizione 3’ e 5’ in alternanza. Il risultato è la
formazione della singola elica.
10.
Il codice genetico: La scoperta del DNA non permetteva ancora di capire come
potesse sintetizzare le proteine. Fu la scoperta del codice che permise di
capire la relazione che c’era tra le basi e gli aminoacidi. Un aminoacido viene
specificato leggendo tre basi dette triplette o codon . Ad ogni
tripletta corrisponde un determinato aminoacido, esistono più triplette che
specificano lo stesso aminoacido. Questo è dovuto al fatto che il codice è
degenerato, ovvero esistono solo venti aminoacidi le quattro basi combinate a triplette danno
64 combinazioni. La regola è 4 3 tra queste combinazioni bisogna eliminare una tripletta
di inizio lettura detta start che
risponde alla sequenza AUG, la stessa sequenza specifica la metionina se
si trova non all’inizio della catena. Altre tre vanno eliminate perché sono
segnali di fine lettura o di stop che sono UUA, UAG, UGA. Rimangono
60 combinazioni per soli venti aminoacidi, per questo motivo abbiamo triplette
diverse per lo stesso aminoacido. Si
dice che il codice è universale ed è vero perché è lo stesso per tutti gli
organismi viventi. In alcuni microrganismi vi sono però delle triplette che non
bloccano la lettura ma specificano diversi aminoacidi. Adesso parliamo di
sintesi proteica ma questo è un altro capitolo.
Allora parliamo di sintesi proteica
Il
processo non è molto semplice la comprensione di questi processi molto complessi necessita di attenzione studio
e applicazione.
Ogni aminoacido viene attivato attraverso
una serie di processi, la prima reazione è l’attivazione dell’aminoacido con
ATP per formare un complesso AMP - AMINOACIL. Successivamente si forma il
complesso con t RNA, la reazione è
catalizzata da una serie di enzimi le aminoacil-t RNA sintetasi.
Ogni enzima è specifico per l’aminoacido e
per il t RNA nel caso di aminoacidi con più di un t RNA lo stesso enzima può
legare indifferentemente ognuno dei diversi t RNA relativi all’aminoacido l’enzima è specifico ed orchestra la
reazione. Questi enzimi sono in grado di correggere eventuali accoppiamenti
errati. Ogni acido nucleico t RNA possiede un diverso codice definito anticodon, una specie di tasca
situata dalla parte opposta all’attacco
dell’aminoacido.
|
|
ATP |
|
|
AMP |
+ |
H4P2O7 |
Durante
questa reazione si consumano una molecola di ATP che si scinde in AMP e acido
bi fosforico, spostando l’equilibrio verso l’aminoacido attivato con il t RNA.
L’energia richiesta per detta reazione è quasi zero, perché l’energia derivante
dall’idrolisi del legame estere dell’aminoacil-tRNA equivale a quella del
gruppo fosforico terminale dell’ATP. La reazione è spostata verso sinistra
perché si forma il bi fosfato, in tutto
si consumano due molecole di acido fosforico e si forma una molecola di AMP. L’enzima sintetasi non si dissocia dall’oligo
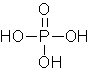
enzima ma rimane attaccata per tutta la
reazione. L’aminoacido è legato al t RNA in posizione 3’ dell’ultimo zucchero
dell’acido nucleico. Il legame avviene tra il gruppo carbossile dell’aminoacido
e il gruppo ossidrile dello zucchero, in posizione 3’ formando un estere.
L’anticodon si accoppia al codon situato sul m
RNA. Il t RNA ha una forma a L e all’
estremità 3’ possiede sempre la medesima sequenza C C A con l’ossidrile in posizione 3’ libero
per poter legare l’aminoacido mediante il gruppo carbossilico. I ribosomi
sono formati da RNA e proteine, di
numero e natura differente, in funzione al tipo di cellula considerata
Ci sono sub unità grandi e
piccole nell’E.coli vi sono due unità una di massa 50 S l’altra di 30 S. Tali unità si possono così schematizzare:
50 S
------------------ 23 S + 5 S + 35 proteine
70 S ------
30 S ----------------- 16 S + 20 proteine
Inizio della sintesi proteica:
Il ribosoma durante la sintesi proteica
viene a dissociarsi solo il 30 S
partecipa alla prima fase, solo in un secondo momento con la scomparsa del fattore di inizio III si
attacca il 50 S, formando il complesso 70 S. I fattori di inizio sono tre ad
ognuno un compito specifico, favoriscono il posizionamento del primo t RNA con
l’aminoacido, sul m RNA a sua volta
posizionano il secondo t RNA in funzione del codon letto. Formano il complesso detto
di inizio sintesi. La prima molecola di t RNA si attacca al codon di inizio
che presenta la tripletta AUG il sito viene detto P o peptidici sul
ribosoma. L’altro dove si attacca il secondo t RNA viene detto sito A.
La fase di allungamento consiste nell’aggiunta degli aminoacidi sino alla
lunghezza specificata. Gli enzimi che
agiscono sono differenti rispetto alla prima fase, il
t RNA legato al primo codon passa il proprio aminoacido, al secondo t
RNA, mediante idrolisi si viene a
liberare il gruppo carbossilico che si lega con
il gruppo amminico libero. L’enzima responsabile del trasferimento è il peptidil
trasferasi. Il secondo t RNA possiede due aminoacidi, cambia di posizione
scorrendo sul m RNA, l’enzima responsabile del processo viene chiamato traslocasi.
Allungamento della sintesi proteica:
Questa fase è caratterizzata dall’aggiunta progressiva
di aminoacidi alla nascente catena proteica. Gli enzimi che partecipano a questa
nuova fase sono i fattori di allungamento, le traslocasi e il GTP dalla sua
idrolisi si trae l’energia necessaria a costruire la catena proteica. Tutto
questo funziona sino all’incontro con il segnale di stop blocco della sintesi,
la proteina viene ad avere la giusta quantità di aminoacidi.
Fase di terminazione:
Al segnale di stop si ha il termine della
sintesi, i fattori di terminazione idrolizzano la proteina dall’ultimo t RNA.
Gli acidi nucleici vengono distrutti il ribosoma viene a dissociarsi e le
proteine vengono assorbite all’interno del reticolo endoplasmatico, dove
subiranno delle modificazioni. Anche l’apparato del Golgi è deputato alla
trasformazione delle molecole proteiche come la formazione delle
glico-proteine.
I geni funzionano tutti
allo stesso tempo
Il modello
proposto è detto operon . Esistono geni repressori che portano
alla formazione di proteine che bloccano la
trascrizione ed esistono geni chiamati promotori che portano alla
formazione di proteine che inibiscono il
repressore e permettono la trascrizione. Accanto ai geni qui descritti abbiamo
i geni strutturali che sono in grado di
codificare proteine, RNA, enzimi
e così via. Nel DNA i siti di legame dell’attivatore si trovano prima del sito
del promotore, mentre i siti di legame del repressore detto operatore si
trovano dopo il sito del promotore. Dopo il sito dell’operatore vi sono i geni
strutturali.
Il modello è così concepito vi sono due siti
di legame uno chiamato promotore ed è la regione contenente i siti di legame dell’RNA polimerasi, l’altra operatore ed è la regione in cui si
legano le molecole del repressore. Se avviene il legame tra l’operatore e la
molecola repressore la sintesi non può avvenire, perché la RNA polimerasi non
può leggere i geni strutturali essendo il sito dell’operatore occupato. Il
repressore, che è una proteina può
essere sintetizzato in forma attiva e quindi funzionare subito bloccando la
sintesi dell’ RNA, oppure in forma inattiva, in questo caso per funzionare
necessita di un'altra molecola presente
nel terreno di coltura chiamato corepressore. Il complesso tra il repressore
corepressore si combina con
l’operatore bloccando la sintesi dell’RNA chiamata trascrizione. Questo
tipo di regolazione viene normalmente chiamata negativa. Esiste
una regolazione positiva dovuta alle molecole degli attivatori che favoriscono la sintesi dell’RNA in quanto
si legano in prossimità dei siti promotori favorendo il legame tra l’RNA
polimerasi ed il sito promotore. Esiste un altro meccanismo dove molecole
denominate induttori possono
legarsi alla molecola del repressore inattivandola e permettendo così, la
sintesi dell’RNA. Questo meccanismo è necessario perché se un prodotto è
presente nella cellula non vi è alcun bisogno di sintetizzarlo, viceversa se un
prodotto è assente nella cellula vi è la necessità di produrlo. Questo
meccanismo quindi dirige la sintesi delle molecole una specie di semaforo dove
con il rosso non si passa, mentre con il verde si passa.
Le duplicazione del DNA sono
tutte simili
Certo che no nelle cellule degli eucarioti
la duplicazione avviene in più punti ed in differenti direzione. Questo è
dovuto alla complessità dei cromosomi che sono molto grandi per essere
duplicati, infatti hanno bisogno di un tempo maggiore rispetto ai batteri. Si
formano molte forcelle di replicazione
che si muovono in direzione differenti. I meccanismi di duplicazione del
DNA degli eucarioti è ancora avvolto da processi non ben conosciuti.
Mutazioni
Le mutazioni sono alterazioni che avvengono
a danno delle molecole che compongono il DNA, alterazioni che possono avere
origine fisica ( raggi UV ) chimica (
sostanze cancerogene ) o biologica ( errori nel meccanismo di duplicazione del
DNA ). Le mutazioni possono portare a:
|
-A-T-T-G-C-G-C- -T-A-A-C-G-C-G- |
GENE NORMALE |
|
-A-T-G-C-G-C- -T-A-C-G-C-G- |
DELEZIONE |
|
-A-T-T-T-G-C-G-C- -T-A-A-A-C-G-C-G- |
INSERZIONE |
|
-G-T-T-G-C-G-C- -C-A-A-C-G-C-G- |
TRANSIZIONE |
|
-A-A-T-G-C-G-C- -T-T-A-C-G-C-G- |
TRANSVERSIONE |
Codice genetico
Il codice genetico è il meccanismo mediante
il quale è possibile sintetizzare le proteine; in altre parole è la sequenza
del DNA che determinava la sequenza delle proteine. Il DNA sintetizzava l’mRNA
acido nucleico che recava la sequenza sotto forma di triplette ( tre basi
adiacenti ) che specificano un determinato aminoacido. La zona dove sono poste
queste sequenze viene detta Codon. L’altra molecola che legge tale
sequenza è il tRNA con una tripletta situata nella zona detta Anticodon,
questo acido nucleico lega anche un aminoacido. L’interazione tra il codon e
l’anticodon permette la traduzione del codice genetico. Ad ogni tripletta letta
corrisponde un aminoacido. Il codice genetico è universale ovvero vale per
tutti i tipi di cellule. Molte osservazioni possono essere fatte:
- Gli aminoacidi possono essere codificati da più
triplette per questo motivo viene detto degenerato.
- Le triplette che non codificano nulla vengono dette non
senso.
- Le triplette possono differire per una sola base
nucleotidica.
Oggi sappiamo
che 4 basi nucleotidiche si possono
combinare tra di loro 3 per volta, il
numero di combinazioni possibili sono:
|
4*4*4 = 64 combinazioni |
Le combinazioni possibili sono 60 |
|
Una combinazione detta di start AUG . Tre dette di stop UAA, UAG, UGA. |
Bisogna eliminare dal calcolo 4 combinazioni 1 di start 3 di stop. |
Se il codice non
fosse degenerato ci sarebbero 20 triplette per codificare 20 aminoacidi, se per
una qualche ragione una delle triplette subisse una mutazione, quel preciso
aminoacidi non potrebbe essere più codificato.